
Ở Việt Nam, chắc hầu hết mọi người đã nghe qua hoặc từng sử dụng nền tảng bán hàng online Tiki. Với bản thân, mình thường sử dụng nền tảng này để đặt sách với chất lượng và giá cả khá tốt. Khi đặt một món hàng nào đó, mình thường đọc các reviews của những người đã mua. Và để nghịch ngợm một tí, mình đã làm dự án nhỏ này: Cào dữ liệu đánh giá từ Tiki và áp dụng Sentiment Analysis lên những đánh giá đó, cụ thể là xét xem một đánh giá là tích cực hay tiêu cực.
Đầu tiên là import những thư viện cần sử dụng:
1
2
3
4
5
6
7
8
9
from selenium.webdriver import Edge
from selenium.webdriver.edge.service import Service
from selenium.webdriver.edge.options import Options
from bs4 import BeautifulSoup
import pandas as pd
import requests
import requests_cache
import json
import time
Cào dữ liệu từ Tiki
Ở đây, mình muốn giới hạn lại dữ liệu nên mình chỉ tập trung vào Sách văn học tiếng Việt mà thôi. Việc đầu tiên, vô trang Tiki xem nó như thế nào đã 😛 Và đây là giao diện của nó:
Mình cần có chiến lược tổng quát để lấy dữ liệu, hmmmm 🤔 Mình sẽ lấy theo cách sau:
- Đầu tiên, mình lấy đường dẫn hoặc ID của từng sản phẩm
- Sau đó, bằng đường dẫn hoặc id đã lấy, mình sẽ tiền hành lấy đánh giá của các sản phẩm đó.
Tại sao lại là đường dẫn hoặc ID của sản phẩm? Tại vì mình có thể lấy dữ liệu bằng hai cách là: parse page source của trang sản phẩm hoặc lấy dựa vào API, nên là mình nghĩ đến hai thứ đó!
Ưu tiên của mình là sử dụng API, vì đơn giản nó đơn giản hơn cách còn lại nhiều 😝 Nên là mình sẽ tìm hiểu xem Tiki có cung cấp API để lấy thông tin sản phẩm không. Mình vào trang của một cuốn sách bất kỳ, ở đây là cuốn: Những Giấc Mơ Ở Hiệu Sách Morisaki của tác giả Yagisawa Satoshi.
Tiếp theo sử dụng công cụ Inspect và vào thẻ Network (nhớ refresh lại page nhé). Và xem mình đã tìm được gì nào:
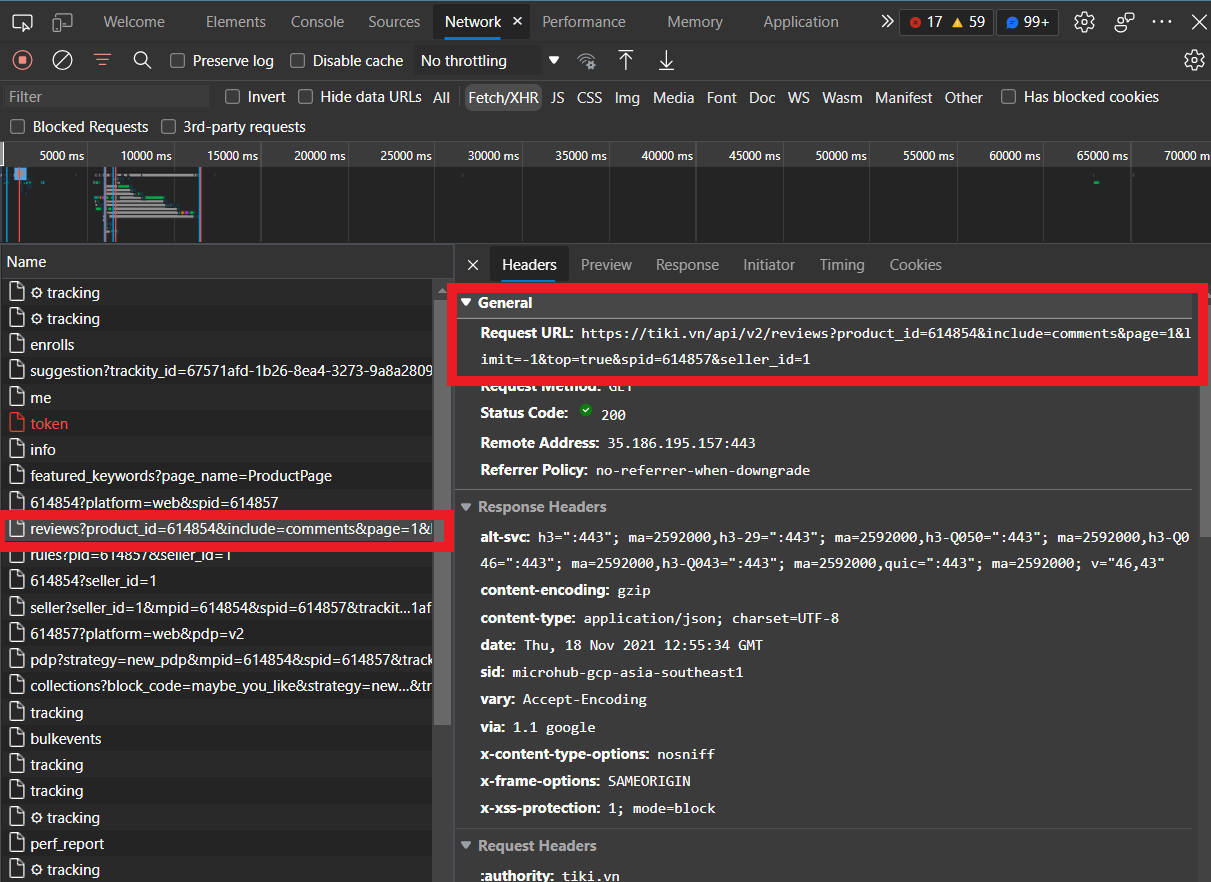
Euréka! Có vẻ đây chính là API để lấy đánh giá sản phẩm, nhưng mình không cần query nhiều tham số như thế, nên chỉ giữ lại một số tham số quan trọng như include=comments (bao gồm nội dung đánh giá), page= (trang) và top=false (kiểu như shuffle các đánh giá). Sau cùng có dạng như thế này:
1
https://tiki.vn/api/v2/reviews?product_id=<product_id>&include=comments&page=<page_num>&top=false
Lấy ID của sản phẩm
Mình đã thử cách tương tự để tìm API lấy danh sách ID của sản phẩm, nhưng có vẻ như là API không hỗ trợ việc này. Do đó mình sẽ sử dụng Selenium để crawl và BeautifulSoup để parse trang web lấy ID của từng sản phẩm.
Đầu tiên, mình lại sử dụng công cụ Inspect để xác định thành phần:
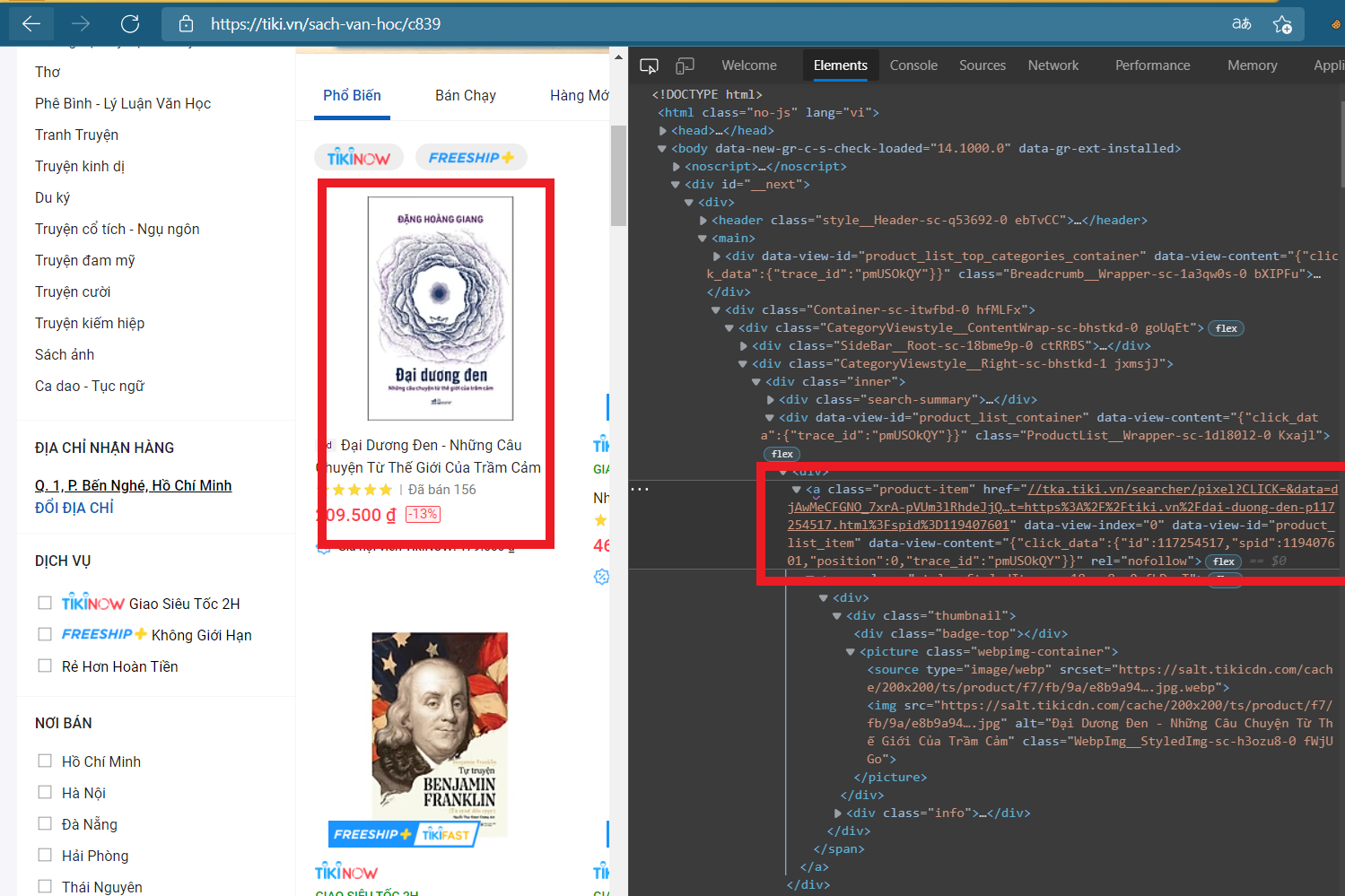
Euréka! Trong thuộc tính data-view-content có chứa ID của sản phẩm. Bắt tay vô làm liền thôi nào 🏄
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
# Cache sleep time (second)
sleep_time = 0.5
# Set up the web driver
edge = Edge(service=Service("D:/Apps/Microsoft Edge/msedgedriver.exe"))
# Init vars
base_url = "https://tiki.vn/sach-van-hoc/c839"
num_pages = 21
max_num_rv = 30
book_ids = []
# Crawl through each page
for page in range(num_pages):
# Go to the i-th page
url = base_url + "?sort=top_seller&page=" + str(page + 1)
edge.get(url)
# Wait for the page loading
time.sleep(load_time)
# Parse the page source with BS4
soup = BeautifulSoup(edge.page_source, 'html.parser')
soup.encoding = 'utf-8'
# Get all the books on the shelf
for book in soup.find_all('a', {'class': 'product-item', 'data-view-id': 'product_list_item'}):
book_ids.append(book['data-view-content'])
# Convert raw data content to book id
book_df = pd.DataFrame()
book_df['id'] = book_ids
book_df['id'] = book_df['id'].apply(lambda x: json.loads(x)['click_data']['id'])
book_df.drop_duplicates(ignore_index=True, inplace=True)
book_df
# Quit the web driver
edge.quit()
| id | |
|---|---|
| 0 | 117238177 |
| 1 | 74021317 |
| 2 | 117254517 |
| 3 | 52789367 |
| 4 | 127929590 |
| ... | ... |
| 1001 | 67325079 |
| 1002 | 71345379 |
| 1003 | 126742915 |
| 1004 | 40824596 |
| 1005 | 95866216 |
1006 rows × 1 columns
Thế là nhẹ nhàng lấy được hơn 1000 quyển sách 😉 Chúng ta đến bước tiếp theo!
Lấy đánh giá của sản phẩm
Mình sẽ ghi lại cú pháp để lấy đánh giá sách bằng API:
1
https://tiki.vn/api/v2/reviews?product_id=<product_id>&include=comments&page=<page_num>&top=false
Trước khi bắt tay vào code, mình sẽ thử request API này và sử dụng công cụ Parse Json online để xem cấu trúc của file response. Mình sẽ tiến hành request với product_id=117254517 và page=1 như sau:
1
https://tiki.vn/api/v2/reviews?product_id=117254517&include=comments&page=1&top=false
Và thu được kết quả:
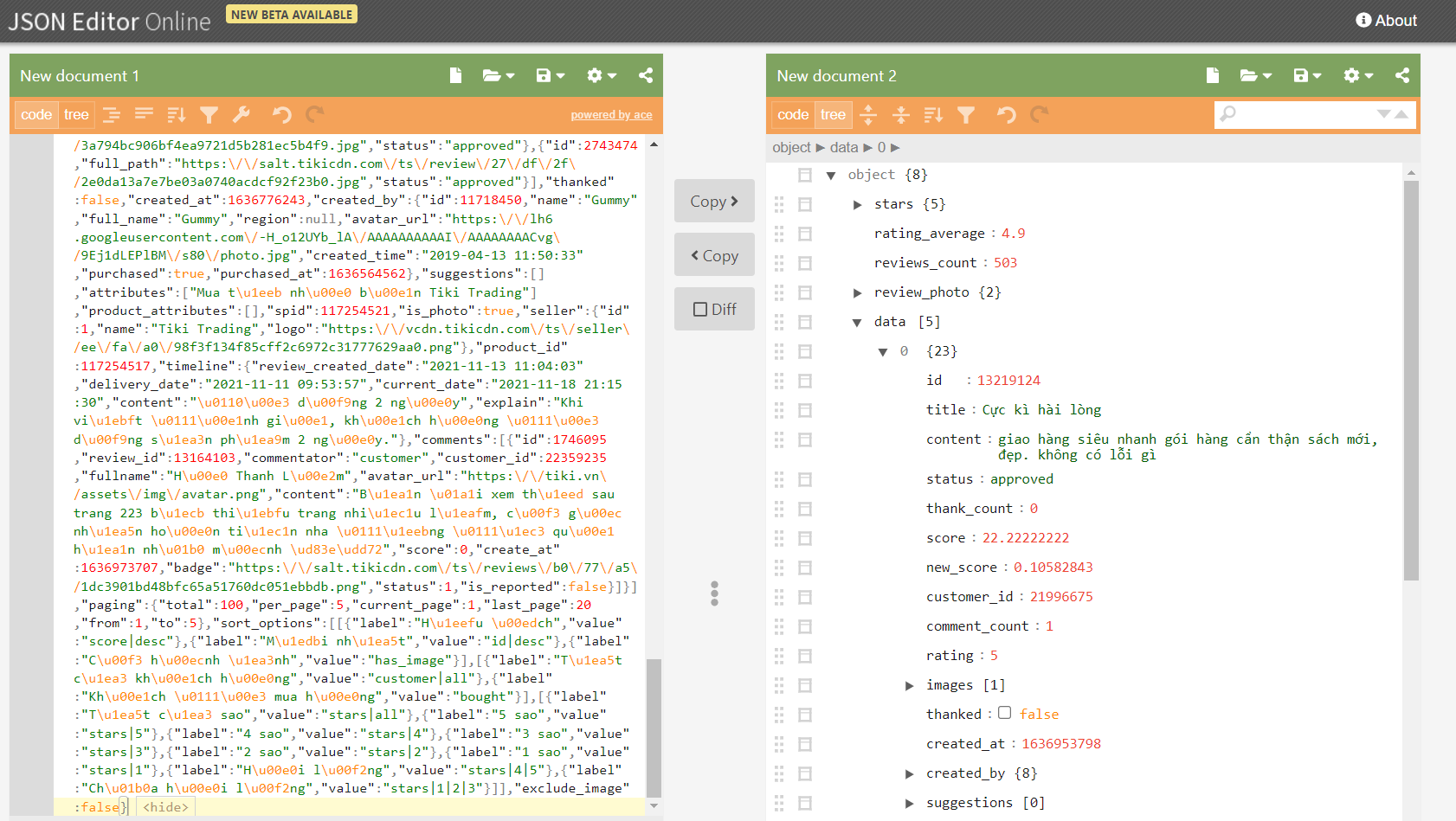
Mình để ý mỗi response sẽ chỉ gồm 5 đánh giá và nằm trong thuộc tính data. Ở project này, mình chỉ cần 2 thuộc tính của đánh giá là rating và content mà thôi. Và để giới hạn lại số lượng đánh giá lấy được, mỗi sản phẩm mình chỉ lấy tối đa 20 trang đánh giá.
Lưu ý rằng: không phải lúc nào đánh giá cũng có nội dung.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
# Set up cache & requests
requests_cache.install_cache(expire_after=None)
headers = {"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36 Edg/95.0.1020.44"}
# Cache sleep time (second)
sleep_time = 0.5
# Use Tiki API to get all reviews of each book
num_pages = 20
contents = []
ratings = []
for id in book_df['id']:
for page in range(num_pages):
url = f"https://tiki.vn/api/v2/reviews?product_id={id}&include=comments&page={page + 1}&top=false"
r = requests.get(url=url, headers=headers)
# Dont want to hit API many times in a short period
if (r.from_cache != True):
time.sleep(sleep_time)
# Failed to GET
if (r.status_code != 200):
break
# Parse the response
raw_data = json.loads(r.content)['data']
for rv in raw_data:
contents.append(rv['content'])
ratings.append(rv['rating'])
# Create a dataframe from the review data
data_df = pd.DataFrame()
data_df['content'] = contents
data_df['rating'] = ratings
# Drop row that has empty content
data_df = data_df[data_df.content != '']
data_df.reset_index(inplace=True, drop=True)
# Save to file
data_df.to_csv('data.csv', index=False)
Ten ten ten ✨ Vậy là mình đã thu thập được dữ mong muốn rồi! Tiếp theo mình sẽ coi sơ qua về phân bố của rating, để xem dữ liệu có “hình dáng” như thế nào.
1
data_df.rating.value_counts()
1
2
3
4
5
6
5 25212
4 3093
3 1318
1 1071
2 781
Name: rating, dtype: int64
Có vẻ như dữ liệu của mình bị unbalanced, khi mà rating đạt 5 sao quá nhiều 😿
Sentiment Analysis
Trong phần này, mình sẽ tiền xử lý dữ liệu đã thu thập và xây dựng mô hình để Sentiment Analysis. Đầu tiên là thêm vào các thư viện cần có:
1
2
3
4
5
6
import numpy as np
import pandas as pd
from pyvi import ViTokenizer
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics import classification_report
Tiền xử lý dữ liệu
Dùng thư viện Pandas để đọc dữ liệu đã được chuẩn bị dưới dạng DataFrame.
1
2
3
# Read the raw data from prepared csv file
raw_df = pd.read_csv('data.csv')
raw_df.head()
| content | rating | |
|---|---|---|
| 0 | truyện hay về bệnh trầm cảm ạ | 5 |
| 1 | Giao hàng nhanh, đóng gói cẩn thận. Rất hài lòng | 5 |
| 2 | Giao trễ 2 ngày so với ngày hẹn. Sách hình thứ... | 5 |
| 3 | Mới tinh, bìa rất là đẹp | 5 |
| 4 | Sách nhiều bụi quá ạ, cứ như Tiki tồn kho rồi ... | 5 |
Đánh nhãn cho dữ liệu
Trước khi bắt đầu xử lý thì mình sẽ nhắc lại mục đích của project này là: xét một đánh giá, xem đánh giá đó là tích cực hay tiêu cực.
Vậy bài toán đã trở thành Binary Classification và chúng ta cần đánh nhãn cho dữ liệu (tích cực hoặc tiêu cực). Ở đây, mình sẽ quy định rằng những đánh giá từ 4 sao trở lên là tích cực (1) và ngược lại từ 3 sao trở xuống là tiêu cực (0).
Nhưng mà “đời không như là mơ”, dữ liệu chúng ta bị unbalanced nghiêm trọng khi rating 5 sao đánh bay mọi loại rating khác 🏝️ Do đó để dữ liệu được balanced hơn mình sẽ không lấy hết dữ liệu nhãn tích cực (1) mà chỉ lấy số lượng xấp xỉ dữ liệu của nhãn còn lại mà thôi.
Thế nhưng cứ để nguyên mà lấy hay sao? Tất nhiên là không, mình sẽ ưu tiên lấy những đánh giá được viết dài hơn là viết ngắn.
1
2
3
# The longer the better
raw_df['len'] = raw_df.content.apply(lambda x: len(x))
raw_df.sort_values(by=['len'], ascending=False, ignore_index=True, inplace=True)
Xong xuôi rồi thì mình tiến hành đánh nhãn thôi:
1
2
3
4
5
6
# Negative sentiment (rating <= 3)
neg_df = raw_df[raw_df.rating < 4].copy()
neg_df.reset_index(inplace=True, drop=True)
neg_df['label'] = 0
neg_df.drop(labels=['rating', 'len'], axis=1, inplace=True)
neg_df
| content | label | |
|---|---|---|
| 0 | NGƯỜI RU NGỦ\n\n3.75/ 5\nMình đã mua cuốn ... | 0 |
| 1 | NHÀ ẢO THUẬT ĐEN VÀ VỤ ÁN MẠNG TẠI THỊ TRẤN KH... | 0 |
| 2 | đoạn review này mình copy từ bài review của an... | 0 |
| 3 | Đây là một cuốn sách nối liền với tuổi xuân củ... | 0 |
| 4 | Hôm nay ngày 26/7/2020 là được 2 tuần từ lúc m... | 0 |
| ... | ... | ... |
| 3165 | Sách hơi hỏng | 0 |
| 3166 | Bị rách bìa | 0 |
| 3167 | Rất buồn! | 0 |
| 3168 | Sách bẩn | 0 |
| 3169 | oke | 0 |
3170 rows × 2 columns
1
2
3
4
5
6
# Positive sentiment (rating >= 4)
pos_df = raw_df[raw_df.rating > 3][:3500].copy()
pos_df.reset_index(inplace=True, drop=True)
pos_df['label'] = 1
pos_df.drop(labels=['rating', 'len'], axis=1, inplace=True)
pos_df
| content | label | |
|---|---|---|
| 0 | Có quá nhiều cảm xúc mà 258 trang của cuốn “ C... | 1 |
| 1 | 21 bài học cho thế kỷ 21.\nM đọc cuốn này ngoà... | 1 |
| 2 | Một quyển sách hồi ký đầy nhân văn, cảm động v... | 1 |
| 3 | Máu me, u tối, bệnh hoạn. Bất ngờ, ám ảnh, và ... | 1 |
| 4 | Thông tin cơ bản: "Học Viện" của được viết bởi... | 1 |
| ... | ... | ... |
| 3495 | Dịch vậy mà Tiki ship nhanh thấy sợ :')) \nSác... | 1 |
| 3496 | Sách giống hình nhưng mà nhỏ hơn so với những ... | 1 |
| 3497 | "Đau sót biết chừng nào! Không lẽ cuốn sổ này,... | 1 |
| 3498 | Sách nhỏ và mỏng hơn mình nghĩ. Như quyển sổ t... | 1 |
| 3499 | Sách của bác Nguyễn Nhật Ánh lúc nào cũng hay ... | 1 |
3500 rows × 2 columns
1
2
3
4
5
# Merge 2 df
data_df = pd.concat(objs=[pos_df, neg_df], ignore_index=True)
# Shuffle the data
data_df = data_df.sample(frac=1, random_state=17, ignore_index=True)
data_df
| content | label | |
|---|---|---|
| 0 | Bìa sách rất bẩn, có rất nhiều vết xước trông ... | 0 |
| 1 | đơn mình nhận bị thiếu bookcare | 0 |
| 2 | Đã lâu mình ko có cảm giác ngấu nghiến 1 bộ ti... | 1 |
| 3 | Mở hộp ra cầm quyển sách đã cảm thấy vừa tức v... | 0 |
| 4 | Tiki giao hàng sớm hơn dự kiến, app báo 4/10 m... | 1 |
| ... | ... | ... |
| 6665 | Chúng ta đều hướng tư tưởng của mình đến sự bì... | 1 |
| 6666 | Tiki fast báo thứ 5 giao nhưng tận trưa thứ 6 ... | 1 |
| 6667 | sách và bookmrk , postcard đều bị hằn dấu của ... | 0 |
| 6668 | cuốn sách rất ổn. có những đoạn rất cuốn hút. ... | 1 |
| 6669 | Chờ mãi mới thấy sale 50% nên hốt liền tay. Mì... | 1 |
6670 rows × 2 columns
Chuyển dữ liệu thô thành dữ liệu máy có thể học được
Word Embeddings hay Word Vectorization là kỹ thuật giúp ta làm việc đó. Có rất nhiều cách, nhưng ở đây mình sẽ chia sẻ một cách đơn giản giúp các bạn dễ dàng hình dung được là Bag of Words (BoW) (tạm dịch: túi từ) 👝.
Đầu tiền mình có một câu cần được vectorized:
1
Bách_Khôi vừa đẹp_trai lại vừa giỏi.
Chú ý: do đặc trưng của tiếng Việt, một từ gồm nhiều chữ nên mình sẽ dùng dấu
_giữa các chữ của một từ. Và mình coi tên riêng của mình là một từ để dễ làm việc 😊 Ngoài ra cần đảm bảo tính chất nhất quán, ở đây là các từ đều được viết thường.
Vậy ở đây, mình có tập BoW gồm các từ:
1
{bách_khôi; vừa; đẹp_trai; lại; giỏi}
Công việc còn lại thì chỉ là ngồi đếm số lần xuất hiện của từ trong một câu, với câu trên thì mình có:
1
2
3
4
5
6
7
{
bách_khôi: 1;
vừa: 2;
đẹp_trai: 1;
lại: 1;
giỏi: 1
}
hay ngắn gọn hơn ta có được một vector như sau:
1
[1, 2, 1, 1, 1]
Trong project này, mình sẽ sử dụng một cách cải tiến hơn của BoW là TF-IDF. Bạn có thể hiểu đơn giản rằng TF-IDF là một cách đếm các từ mà những từ thường xuất hiện hay hiếm xuất hiện sẽ có trọng số khác nhau.
Yeah, và như ví dụ ở trên thì mình cần tách từ ra và viết thường toàn bộ:
1
2
3
4
# Make sure that all letters are lowercase
data_df.content = data_df.content.apply(lambda x: x.lower())
# Tokenize the reviews
data_df.content = data_df.content.apply(lambda x: ViTokenizer.tokenize(x))
Tiếp theo mình cần loại bỏ stopwords (từ không đóng góp ý nghĩa cho câu) ra khỏi văn bản, mặc dù TF-IDF hỗ trợ “loại bỏ một phần”1 những từ không đóng góp nhiều ý nghĩa, nhưng có vẫn tốt hơn mà.
Ngoài ra một số đánh giá còn chưa emoji và một số dấu câu, chúng ta cũng cần phải loại bỏ chúng!
Ở đây mình đã chuẩn bị sẵn tập các stopwords phổ biến dành cho tiếng Việt. Nhưng chắc chắn là mình còn thiếu rất nhiều từ, do đó rất mong nhận được sự đóng góp của các bạn.
1
2
3
4
5
# Prepare the Vietnamese stopword set
with open('vietnamese_stopwords.txt', 'r', encoding='utf-8') as file:
stopwords = [line[:-1] if '\n' in line else line for line in file.readlines()]
stopwords = set(stopwords)
print(stopwords)
1
{'được', 'lại', 'điều', 'nhưng', 'bên', 'đến_nỗi', 'có', 'nữa', 'ớ', 'phải', 'bị', 'gì', 'sau', 'cho', 'vì', 'sự', 'ồ', 'khi', 'a', 'vào', 'nó', 'nha', 'các', 'do', 'tại', 'về', 'vừa', 'là', 'ra', 'mỗi', 'cả', 'cũng', 'đây', 'rằng', 'chỉ', 'này', 'ô', 'ừ', 'nên', 'sẽ', 'cần', 'trên', 'quá', 'ạ', 'dưới', 'á', 'tôi', 'thì', 'nếu', 'cái', 'trước', 'mình', 'bạn', 'một_cách', 'theo', 'qua', 'thôi', 'à', 'bởi', 'đã', 'như', 'vẫn', 'của', 'chưa', 'đó', 'tui', 'nơi', 'việc', 'đều', 'đang', 'o', 'với', 'rất', 'ngay', 'thế', 'cứ', 'lúc', 'vậy', 'cùng', 'nhiều', 'để', 'từng', 'nhe', 'nhé', 'từ', 'ê', 'so', 'có_thể', 'những', 'nè', 'mà', 'và', 'càng', 'rồi', 'chứ', 'chuyện', 'lên'}
Chuẩn bị xong hết rồi thì tiến hành xử lý dữ liệu thôi.
1
2
3
4
5
6
7
8
9
clean_corpus = data_df.content.copy()
# Drop the stopwords
clean_corpus = [[word for word in rv.split() if word not in stopwords] for rv in clean_corpus]
# Remove emoji and punctuation
clean_corpus = [" ".join([word for word in rv if ('_' in word) or (word.isalpha() == True)]) for rv in clean_corpus]
# Update the data
data_df.content = clean_corpus
# Vectorize the reviews
vectorizer = TfidfVectorizer(min_df=0.2, max_df=0.8, max_features=5000, smooth_idf=True)
Chuẩn bị tập dữ liệu để huấn luyện 🤖
1
2
3
4
5
6
7
8
# Create X set by vectorizing data_df
X = vectorizer.fit_transform(data_df.content)
# Btw create the y set
y = data_df.label
# Create training & testing set
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size=0.3,random_state=17)
Xây dựng models
Trong project này, mình sẽ xây dựng 3 models quen thuộc là: Logistic Regression, Support Vector Machine và Decision Tree.
Vì đã có rất nhiều tài liệu về các models này rồi, nên là mình sẽ không giải thích gì thêm về các models này, mà chỉ cài đặt và sử dụng chúng trong bài toán của mình mà thôi 👍
Okay, bắt đầu nào!
Logistic regression
1
2
3
4
5
6
from sklearn.linear_model import LogisticRegression
lr_model = LogisticRegression(max_iter=500, random_state=17)
lr_model.fit(X_train, y_train)
print(classification_report(lr_model.predict(X_test), y_test))
1
2
3
4
5
6
7
8
precision recall f1-score support
0 0.77 0.78 0.78 938
1 0.81 0.79 0.80 1063
accuracy 0.79 2001
macro avg 0.79 0.79 0.79 2001
weighted avg 0.79 0.79 0.79 2001
Support Vector Machine
1
2
3
4
5
6
from sklearn.svm import SVC
svc_model = SVC(random_state=17)
svc_model.fit(X_train, y_train)
print(classification_report(svc_model.predict(X_test), y_test))
1
2
3
4
5
6
7
8
precision recall f1-score support
0 0.77 0.79 0.78 926
1 0.82 0.80 0.81 1075
accuracy 0.80 2001
macro avg 0.79 0.80 0.80 2001
weighted avg 0.80 0.80 0.80 2001
Decision Tree
1
2
3
4
5
6
from sklearn.tree import DecisionTreeClassifier
tree_model = DecisionTreeClassifier(random_state=17)
tree_model.fit(X_train, y_train)
print(classification_report(tree_model.predict(X_test), y_test))
1
2
3
4
5
6
7
8
precision recall f1-score support
0 0.77 0.74 0.76 993
1 0.76 0.79 0.77 1008
accuracy 0.76 2001
macro avg 0.76 0.76 0.76 2001
weighted avg 0.76 0.76 0.76 2001
Mặc dù tập dữ liệu huấn luyện khá ít và các models chưa được tuning nhưng nhìn chung các mô hình đều cho độ chính xác khoảng 80%. Một con số khá ấn tượng phải không? 👍
Tiếp theo mình sẽ thử dự đoán một số đánh giá xem thái độ của người viết là tích cực hay tiêu cực.
Dự đoán thái độ người viết đánh giá
Mình đã chuẩn bị một số câu đánh giá như sau:
- Tích cực:
- Thích cuốn sách này! Tiki giao hàng nhanh, đóng gói kĩ càng
- Thật sự lâu rồi mới đọc một cuốn sách tuyệt vời như thế này 🥰🥰🥰
- Tạm ổn :) một cuốn sách nhẹ nhàng cho những tâm hồn nặng trĩu
- Tiêu cực:
- Giao hàng chậm, hàng kém chất lượng
- Khá thất vọng! Bìa móp méo
- Quá tệ! Sách bị nhăn góc hết trơn! 😢😢
- Nội dung sách tốt nhưng về khâu đóng gói của Tiki là quá tệ, cho 2 sao thôi!
Mình vẫn sẽ áp dụng các bước cơ bản tiền xử lý dữ liệu như: chuyển câu thành viết thường, tokenize rồi cuối cùng là vectorize.
1
2
3
4
5
6
7
8
9
10
exs = ['Giao hàng chậm, hàng kém chất lượng', 'Khá thất vọng! Bìa móp méo',
'Thích cuốn sách này! Tiki giao hàng nhanh, đóng gói kĩ càng', 'Quá tệ! Sách bị nhăn góc hết trơn! 😢😢',
'Thật sự lâu rồi mới đọc một cuốn sách tuyệt vời như thế này 🥰🥰🥰', 'Tạm ổn :) một cuốn sách nhẹ nhàng cho những tâm hồn nặng trĩu',
'Nội dung sách tốt nhưng về khâu đóng gói của Tiki là quá tệ, cho 2 sao thôi!']
# Make sure that all letters are lowercase
exs = [ex.lower() for ex in exs]
# Tokenize the reviews
exs = [ViTokenizer.tokenize(ex) for ex in exs]
# Vectorize the reviews
X_pred = vectorizer.transform(exs)
Và đây là kết quả của các mô hình:
- Logistic Regression: [0 0 1 0 1 1 0]
- Support Vector Machine: [0 0 1 0 1 1 0]
- Decision Tree: [0 0 0 0 1 1 0]
Khá là chính xác đó chứ, hohohoho 😂😂😂😂
Lời cuối
Sentiment Analysis (tạm dịch: phân tích quan điểm) là một lĩnh vực quan trọng trong Natural Language Processing và được ứng dụng trong rất nhiều lĩnh vực, đặc biệt là lĩnh vực E-Commerce.
Project này chỉ là một góc nhìn rất nhỏ và đơn sơ về Sentiment Analysis mà thôi. Bạn có thể cải tiến project này hơn nữa bằng một số cách như sau:
- Crawl thêm dữ liệu đánh giá sách.
- Bổ sung thêm stopwords.
- Xử dụng các kỹ thuật Word vectorization khác.
- Cải tiến mô hình học máy: chọn mô hình, tuning tham số.
- Deep learning.
Đây là bài viết đầu tiên của mình, nên rất mong nhận được sự góp ý từ các bạn 🤓
TF-IDF đánh trọng số nhỏ nhằm giảm sự “cống hiến”. ↩