
Bài toán OCR
Optical Character Recognition hay OCR (tạm dịch: Nhận dạng kí tự quang học). Là bài toán nhận diện và chuyển đổi chữ hay đoạn văn trong bức ảnh thành văn bản máy tính. Đây là một bài toán rất phổ biến trong lĩnh vực Computer Vision (tạm dịch: thị giác máy tính). Nó mang lại rất nhiều ứng dụng thực tế như: số hóa thư viện, nhận dạng Căn cước công dân/Chứng minh nhân dân, nhận dạng biển số xe,…
Trong project lần này, mình sẽ xây dựng một ứng dụng OCR có khả năng nhận dạng và chuyển đổi một bức ảnh chứa câu chữ Nôm thành văn bản máy tính.
Chữ Nôm
Đầu tiên, chúng ta sẽ tìm hiểu một chút về chữ Nôm. Theo Wikipedia:
Chữ Nôm (𡨸喃), còn được gọi là Quốc âm (國音) hay Quốc ngữ (國語) là loại văn tự ngữ tố - âm tiết dùng để viết tiếng Việt. Đây là bộ chữ được người Việt tạo ra dựa trên chữ Hán, các bộ thủ, âm đọc và nghĩa từ vựng trong tiếng Việt. Chữ Nôm bắt đầu hình thành và phát triển từ thế kỷ 10 đến thế kỷ 20. Sơ khởi, chữ Nôm thường dùng ghi chép tên người, địa danh, sau đó được dần dần phổ cập, tiến vào sinh hoạt văn hóa của quốc gia. Vào thời Nhà Hồ ở thế kỷ 14 và Nhà Tây Sơn ở thế kỷ 18, xuất hiện khuynh hướng dùng chữ Nôm trong văn thư hành chính. Đối với văn học Việt Nam, chữ Nôm có ý nghĩa đặc biệt quan trọng khi là công cụ xây dựng nền văn học cổ truyền kéo dài nhiều thế kỷ.
Mặc dù chữ Nôm mang ý nghĩa cực kỳ quan trọng, thế nhưng ngày nay, có vẻ như chữ Nôm đang dần bị quên lãng. Số lượng người trẻ biết đọc và viết chữ Nôm ngày càng ít, chủ yếu là những bạn học hay nghiên cứu về Hán - Nôm mà thôi. Do đó, với mong muốn đưa chữ Nôm xinh đẹp và giàu giá trị lịch sử này đến gần hơn với thế hệ trẻ, mình đã phát triển project này (●’◡’●).
Chuẩn bị tập dữ liệu
Bất kì mô hình học máy nào cũng cần có tập dữ liệu huấn luyện, vì vậy trước khi xây dựng mô hình, mình cần chuẩn bị tập dữ liệu được gán nhãn phù hợp với bài toán Nôm OCR. Thể nhưng, thật sự rất khó để tìm được các nguồn dữ liệu liên quan đến chữ Nôm. Do đó, để cho dễ dàng, mình sẽ tự sinh tập dữ liệu (●’◡’●).
Cụ thể hơn, mình sẽ sinh hình ảnh các câu chữ Nôm có độ dài ngẫu nhiên từ 6 - 12 ký tự Nôm trong 1000 chữ Nôm phổ biến từ font chữ NomNaTong.
 Thống kê 1000 chữ Nôm thông dụng từ trang hvdic.thivien.net
Thống kê 1000 chữ Nôm thông dụng từ trang hvdic.thivien.net
Ngoài ra, mình cũng sẽ cố định kích thước của các hình ảnh đầu ra với chiều cao là 64 px và chiều rộng là 256 px.
Okay, mình sẽ tiến hành sinh các hình ảnh chứa câu và font bằng chữ Nôm mong muốn bằng hàm như sau:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
from PIL import Image, ImageDraw, ImageFont
def create_text_image(self, text, font_ttf, idx, font_size):
try:
image = Image.new("RGB", (IMG_WIDTH, IMG_HEIGHT), (255, 255, 255))
draw = ImageDraw.Draw(image)
font = ImageFont.truetype(font_ttf, font_size)
w, h = draw.textsize(text, font=font)
draw.text(((IMG_WIDTH - w) / 2, (IMG_HEIGHT - h) / 2), text, (0, 0, 0), font=font)
if self.save_image:
image.save(f'{self.image_folder}/{idx}.jpg')
self.log.append({'font': font_ttf, 'image':f'{idx}.jpg'})
return image
except Exception as e:
self.errors.append({'font': font_ttf, 'errors': str(e)})
return None
Và đây là kết quả:

Ngoài sinh hình ra, đừng quên lưu lại nhãn tương ứng của từng hình nhé ☜(゚ヮ゚☜).
Cuối cùng, bộ dữ liệu của mình gồm 30000 hình ảnh cho tập train, 3000 hình ảnh cho tập validation và 1000 hình ảnh cho tập test. Thế nhưng, để ý rằng hình ảnh của mình sinh ra chỉ là ảnh trắng đen (grayscale) mà thôi. Do đó, việc đọc dữ liệu từ từng hình ảnh có đuôi .jpg là không tối ưu. Vì vậy, mình đã lưu trữ bộ dữ liệu mình dưới dạng file csv, với mỗi dòng tương ứng với một hình và có số cột bằng chiều rộng x chiều cao (256 x 64) của hình. Thế là xong phần dữ liệu, mình sẽ bắt tay vào bước xây dựng mô hình thôi (●’◡’●).
Xây dựng mô hình Nôm OCR
Ở project lần này, mình sẽ sử dụng mô hình CRNN + CTC Loss được đề xuất bởi Baoguang Shi cùng cộng sự. Do cấu trúc phù hợp cũng như tính hiệu quả mang lại, mô hình CRNN + CTC Loss là một mô hình được sử dụng khá phổ biến trong các bài toán OCR. Ở đây, để ngắn gọn bài viết, mình sẽ không đi quá sâu vào cấu trúc của mô hình, các bạn có hứng thú thì có thể tìm đọc thêm tại [1] và [2].
CRNN
CRNN là viết tắt của cụm từ Convolutional Recurrent Neural Network (Tạm dịch: Mạng nơ-ron tích chập hồi quy). Như cái tên đã thể hiện, CRNN là sự kết hợp của hai mạng nơ-ron nổi tiếng là CNN và RNN. Trong đó, CNN có nhiệm vụ trích xuất các đặc trưng của hình ảnh (viền, cạnh…) đầu vào thành các Feature vectors được gọi là Feature sequence. Từ Feature sequence, RNN sẽ học các thông tin được tổng hợp trong chuỗi các vector này, từ đó đưa ra output phù hợp.
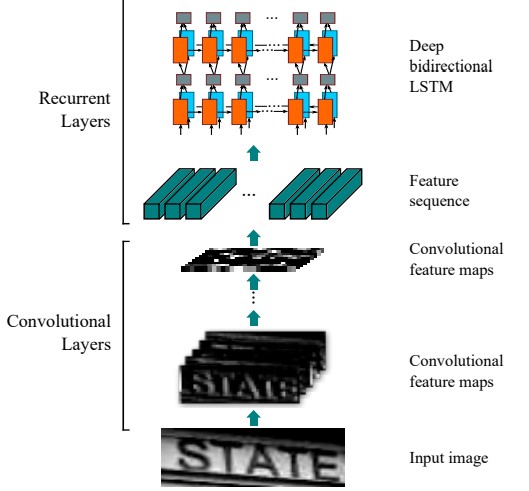 Kiến trúc của mô hình CRNN
Kiến trúc của mô hình CRNN
Receptive Field
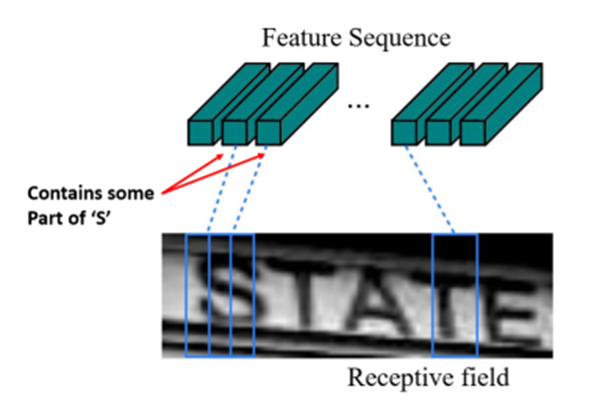 Minh họa Receptive field và Feature vector
Minh họa Receptive field và Feature vector
Như hình minh họa ở trên, mỗi Feature vector trong Feature sequence sẽ tương ứng với một Receptive field (tạm dịch: khung nhìn) trong bức ảnh. Vì mình có hình ảnh đầu vào có kích thước cố định là 256 x 64 và có độ dài chuỗi là từ 6 đến 12 kí tự. Nên mình đã tùy chỉnh kích thước các Receptive field này thành một con số hợp lí là 16 x 64, tức chia hình ảnh đầu vào thành 16 Receptive field. Chúng ta có thể tùy chỉnh kích thước này bằng cách thay đổi số lượng MaxPool layers trong kiến trúc. 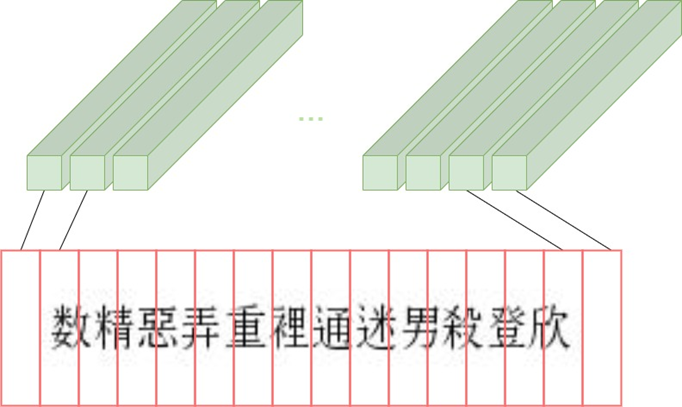 Minh họa Receptive fields với dữ liệu tự sinh
Minh họa Receptive fields với dữ liệu tự sinh
Qua đó, chúng ta có thể thấy rằng, việc tùy chỉnh kích thước Feature vector hay nói cách khác là kích thước của Receptive Field cho phù hợp là vô cùng quan trọng (●’◡’●).
CTC Loss
Tại sao chúng ta phải sử dụng thêm CTC Loss? Và CTC Loss là gì?
Vấn đề của CRNN là đầu ra của nó chứa các kí tự lặp lại với nhau. Điều này có thể xảy ra khi mà một kí tự quá to hoặc nằm giữa hai Receptive field kế bên nhau.
Do đó, để khắc phục vấn đề này, chúng ta sử dụng thêm một hàm mất mát tên là CTC (Connectionist Temporal Classification). Hiểu một cách đơn giản, hàm này sẽ đi tìm tất cả các alignments (tạm dịch: tổ hợp) các trường hợp có thể có và chọn ra một alignment phù hợp nhất.
Tiếp theo, chúng ta sẽ hành cài đặt mô hình bằng thư viện Tensorflow V2, mình có tham khảo code tại đây:
Đầu tiên là hàm CTC Loss:
1
2
3
4
5
6
7
8
from keras import backend as K
def ctc_lambda_func(args):
y_pred, labels, input_length, label_length = args
# the 2 is critical here since the first couple outputs of the RNN
# tend to be garbage
y_pred = y_pred[:, 2:, :]
return K.ctc_batch_cost(labels, y_pred, input_length, label_length)
Tiếp theo là nhân vật chính của chúng ta - CRNN:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
from keras.models import Model
from keras.layers import Input, Conv2D, MaxPooling2D, Reshape, Bidirectional, LSTM, Dense, Lambda, Activation, BatchNormalization, Dropout
def get_model(train):
input_data = Input(shape=(IMG_WIDTH, IMG_HEIGHT, 1), name='input')
inner = Conv2D(32, (3, 3), padding='same', name='conv1', kernel_initializer='he_normal')(input_data)
inner = BatchNormalization()(inner)
inner = Activation('relu')(inner)
inner = MaxPooling2D(pool_size=(2, 2), name='max1')(inner)
inner = Conv2D(64, (3, 3), padding='same', name='conv2', kernel_initializer='he_normal')(inner)
inner = BatchNormalization()(inner)
inner = Activation('relu')(inner)
inner = MaxPooling2D(pool_size=(2, 2), name='max2')(inner)
inner = Dropout(0.3)(inner)
inner = Conv2D(128, (3, 3), padding='same', name='conv3', kernel_initializer='he_normal')(inner)
inner = BatchNormalization()(inner)
inner = Activation('relu')(inner)
inner = MaxPooling2D(pool_size=(2, 2), name='max3')(inner)
inner = Dropout(0.3)(inner)
inner = Conv2D(256, (3, 3), padding='same', name='conv4', kernel_initializer='he_normal')(inner)
inner = BatchNormalization()(inner)
inner = Activation('relu')(inner)
inner = MaxPooling2D(pool_size=(2, 2), name='max4')(inner)
inner = Dropout(0.3)(inner)
# CNN to RNN
inner = Reshape(target_shape=((16, 1024)), name='reshape')(inner)
inner = Dense(64, activation='relu', kernel_initializer='he_normal', name='dense1')(inner)
## RNN
inner = Bidirectional(LSTM(256, return_sequences=True), name = 'lstm1')(inner)
inner = Bidirectional(LSTM(256, return_sequences=True), name = 'lstm2')(inner)
## OUTPUT
inner = Dense(NUM_OF_CHARACTERS, kernel_initializer='he_normal',name='dense2')(inner)
y_pred = Activation('softmax', name='softmax')(inner)
model = Model(inputs=input_data, outputs=y_pred)
labels = Input(name='gtruth_labels', shape=[MAX_STR_LEN], dtype='float32')
input_length = Input(name='input_length', shape=[1], dtype='int64')
label_length = Input(name='label_length', shape=[1], dtype='int64')
ctc_loss = Lambda(ctc_lambda_func, output_shape=(1,), name='ctc')([y_pred, labels, input_length, label_length])
model_final = Model(inputs=[input_data, labels, input_length, label_length], outputs=ctc_loss)
if (train):
print(model_final.summary())
return model_final, model
else:
return model
Huấn luyện mô hình
Sau khi đã có được mô hình, mình sẽ tiến hành huấn luyện trên tập dữ liệu đã chuẩn bị trước.
Đọc dữ liệu
Mặc dù tập hình ảnh đã được tối ưu bằng cách lưu vào một file csv, nhưng nếu mình đọc bằng thư viện pandas như thông thường thì có thể bị tràn RAM. Do đó, ở đây mình sẽ đọc dữ liệu theo từng Chunk, với kích thước của mỗi Chunk là 5000. Ngoài ra để phù hợp với đầu vào của mô hình, mình sẽ chuyển dữ liệu thành các mảng numpy và xoay ảnh. Bên cạnh đó, để thuận tiện cho tính toán, mình cũng sẽ normalize dữ liệu (Min-max normalization) luôn (●’◡’●).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
train_x = np.empty(shape=(0, IMG_WIDTH*IMG_HEIGHT))
print('Train dataset...')
if TRAIN_SIZE > CHUNK_SIZE:
train_df = pd.read_csv(TRAIN_DATASET_FILE, header=None, chunksize=CHUNK_SIZE)
for idx, df in enumerate(train_df):
if idx >= int(np.ceil(TRAIN_SIZE/CHUNK_SIZE)):
break
train_x = np.concatenate([train_x, df[:] / 255], axis=0)
print(f'Read Train dataset chunk [{idx}]')
else:
train_df = pd.read_csv(TRAIN_DATASET_FILE, header=None)
train_x = train_df[:TRAIN_SIZE] / 255 # normalize
train_x = np.array(train_x).reshape(-1, IMG_WIDTH, IMG_HEIGHT, 1).astype(np.float32)
print(f'Train dataset shape: {train_x.shape}')
Sau khi đọc xong hình ảnh, mình tiếp tục đọc nhãn ứng với tập dữ liệu. Ở đây, mình cần encode các chuỗi kí tự của nhãn thành vector số tương ứng bằng hàm label_to_num.
1
2
3
4
5
6
def label_to_num(label):
label_num = []
for ch in label:
label_num.append(ALPHABET.find(ch))
return np.array(label_num)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
with open(TRAIN_LABEL_FILE, 'r', encoding='utf-8') as train_label_file:
train_labels = train_label_file.readlines()
train_labels = [label.strip() for label in train_labels]
### ---------------------------------------------------------
### train_y: true labels converted to numbers and padded with -1.
### the length of each label is equal to MAX_STR_LEN
### train_label_len: contains the length of each true label (without padding)
### train_input_len: length of predicted label = NUM_OF_TIMESTEPS - 2
### train_output: is a dummy output for CTC loss
### ---------------------------------------------------------
train_y = np.ones([TRAIN_SIZE, MAX_STR_LEN]) * -1
train_label_len = np.zeros([TRAIN_SIZE, 1])
train_input_len = np.ones([TRAIN_SIZE, 1]) * (NUM_OF_TIMESTEPS-2)
train_output = np.zeros([TRAIN_SIZE])
for i in range(TRAIN_SIZE):
train_label_len[i] = len(train_labels[i])
train_y[i, 0:len(train_labels[i])] = label_to_num(train_labels[i])
Mình sẽ đọc dữ liệu tương tự cho tập validation.
Huấn luyện
Sau khi có đọc dữ liệu thành công, mình sẽ tiến hành khởi tạo vào huấn luyện mô hình với một số tùy chỉnh sau về Hyperparameters:
Optimizer: Adam optimizer với learning_rate là 0.0001Batch size: 128Epochs: 60
❗Lưu ý: các hyperparameters này chưa được mình tuned tối ưu nha.
1
2
3
4
5
6
7
8
9
10
11
model, pred_model = Model.get_model(train=True)
# the loss calculation occurs elsewhere, so we use a dummy lambda function for the loss
model.compile(loss={'ctc': lambda y_true, y_pred: y_pred}, optimizer=Adam(learning_rate = 0.0001))
model.fit(x=[train_x, train_y, train_input_len, train_label_len],
y=train_output,
validation_data=([valid_x, valid_y, valid_input_len, valid_label_len], valid_output),
epochs=60,
batch_size=128,
callbacks=[model_checkpoint_callback, model_early_stopping_callback]
)
Về thời gian huấn luyện, mình mất khoảng hơn 1h khi huấn luyện mô hình trên Google Colab.
Đánh giá mô hình
Để đánh giá mô hình, mình sử dụng độ đo Accuracy trên tập test. Cụ thể là phần trăm kí tự đoán đúng trên tổng số ký tự. Ngoài ra, ngược lại khi encode dữ liệu đầu vào, mình cần phải decode output từ vector số thành một chuỗi các kí tự bằng hàm num_to_label
1
2
3
4
5
6
7
8
def num_to_label(num):
ret = ""
for ch in num:
if ch == -1: # CTC Blank
break
else:
ret+=ALPHABET[ch]
return ret
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
df = pd.read_csv(f'{data_path}/{DATASET_FILE_NAME}', header=None)
test_x = df[:num_imgs] / 255
test_x = np.array(test_x).reshape(-1, IMG_WIDTH, IMG_HEIGHT, 1)
preds = model.predict(test_x)
preds = preds[:, 2:, :]
decoded = K.get_value(K.ctc_decode(preds, input_length=np.ones(preds.shape[0])*preds.shape[1],
greedy=True)[0][0])
for i in tqdm(range(num_imgs)):
pred_label = num_to_label(decoded[i])
true_label = true_labels[i]
total_char += len(true_label)
for _ in range(min(len(pred_label), len(true_label))):
if(pred_label[_] == true_label[_]):
correct_char += 1
print('---------------------------------------')
print('Correct characters predicted : %.2f%%' %(correct_char*100/total_char))
Kết quả tốt nhất cho đến thời điểm hiện tại mình đạt được là 89.31% (●’◡’●).
Deploy mô hình bằng FlaskAPI
Mục tiêu của mình là xây dựng một web application. Cụ thể hơn, người dùng sẽ chọn tải lên một bức ảnh chứa đoạn chữ Nôm, nhấn nút Process, mô hình xử lý và trả lại kết quả.
Trong project này, mình sử dụng framework Flask để thực hiện. Cách làm khá đơn giản, mình chỉ cần lưu lại model của mình dưới dạng file h5. Sau đó load model bằng file h5 đã lưu, viết API bắt model xử lý hình ảnh của người dùng và trả về kết quả (●’◡’●). Và đây là giao diện trang web sau khi hoàn thành:
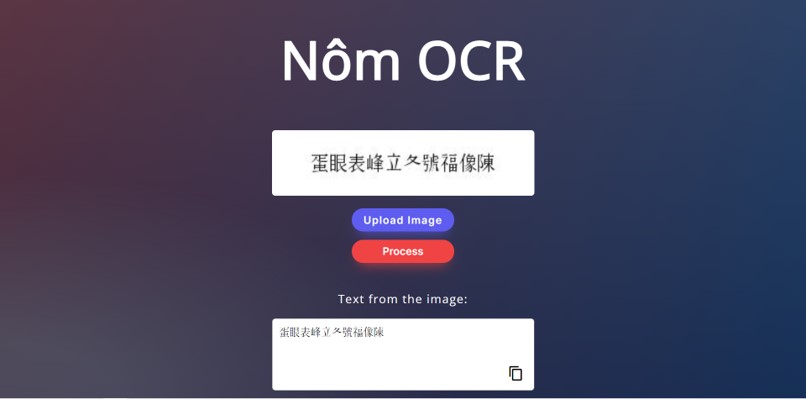 Giao diện của trang web
Giao diện của trang web
Tổng kết
Điều hạn chế rõ ràng nhất của project lần này chính là tính ứng dụng vào thực tiễn, do bộ dữ liệu được sinh ra từ font chữ máy tính. Do đó, bạn có thể hoàn toàn cải tiến mô hình này với bộ dữ liệu chữ Nôm trong thực tế (đền, chùa, văn tự cổ, …) để mô hình có thể áp dụng vào thực tế cuộc sống. Bên cạnh đó, do chữ Nôm được sáng tạo nên từ chữ Hán. Do đó, việc transfer learning (tạm dịch: học chuyển giao) từ mô hình OCR chữ Hán sang OCR chữ Nôm chắc chắn sẽ nâng cao performance của mô hình lên rất nhiều (●’◡’●). Qua dự án lần này, mình đã được học thêm và vận dụng một số kiến thức và kĩ năng như:
- Chữ Nôm: để có thể làm project này, mình đã research một xíu về chữ Nôm như nguồn gốc, cách viết hay một số tác phẩm nổi tiếng viết bằng chữ Nôm. Còn đây là tên của mình khi viết bằng chữ Nôm: 武佰恢 (Võ Bách Khôi) ✨✨.
- Chuẩn bị dữ liệu: sinh hình ảnh một câu văn từ font chữ máy tính.
- Lưu và đọc dữ liệu hiệu quả: do số lượng dữ liệu lớn, nên mình cần phải lưu với định dạng tối ưu, cũng như có phương pháp đọc một cách hợp lí.
- Xây dựng mô hình CRNN + CRC Loss với TensorflowV2: việc đọc và hiểu rõ mô hình và dữ liệu giúp mình tinh chỉnh kiến trúc mô hình một cách tối ưu hơn (tinh chỉnh Receptive field).
- Deploy model bằng Flask: học thêm một số kiến thức về CSS, Javascript và cách viết API bằng Flask.
Cảm ơn bạn đã đọc đến cuối bài. ༼ つ ◕_◕ ༽つ❤