
While researching on CV field, I wrote this blog as a cheat sheet to recap and review my study. The aim of this blog is to cover most of the things you need to build Convolutional layers from scratch using PyTorch. It includes some interesting kinds of stuff:
- What convolutional and pooling layers are?
- How to calculate their output’s dimension?
- What is on the earth called Dilated Convolution?
- Transposed convolution or Deconvolution
By the way, this is the first time that I write a blog in English. So please feel free to comment if I’ve missed anything 😽😽.
Convolutional & Pooling operation
Convolution operation
In the convolutional layer, we use a thing called “Kernel” or “Filter” to operate the convolutional operation. The kernel slides through the image i.e. a tensor of pixels and performs element-wise multiplication operation. The following gif shows how the convolutional operation works. Applying a kernel (blue small matrix) on the image (left big matrix), we have a feature map (right purple matrix).
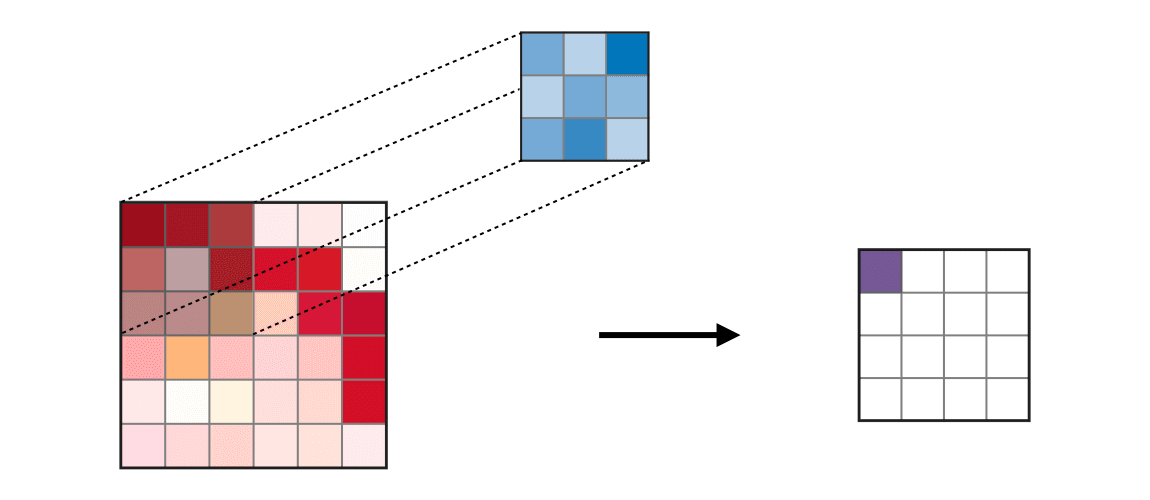 Convolutional operation (Source: Standford)
Convolutional operation (Source: Standford)
This feature map can be used for many things such as the feedstock for deep learning networks to classify or caption images, or the representative of image for the image retrieval task.
Furthermore, we can control this operation through some hyperparameters which are stride (controls the amount of movement over the image), kernel size, and padding (adding zero-border). About the padding, there are two common types of results to this operation: reduced dimensionality or remaining the same. The former approach is called “Valid padding” and the latter is called “Same padding”. The following image illustrates how this works.
 Valid Padding vs Same Padding (Source: AI Geek Programmer)
Valid Padding vs Same Padding (Source: AI Geek Programmer)
Pooling operation
The main idea for using the Pooling operation is to reduce the dimensionality of the feature map. Moreover, it is also used for extracting dominant features that are rotational and positional invariant.
Its computing process is quite the same as the convolutional operation. Namely, there are two common types of this pooling operation: Max pooling and Average Pooling. As the name implies, Max pooling gets the max value of all elements in the receptive field i.e. the portion of the image covered by the kernel. On the other hand, Average pooling gets the average value of all elements in the receptive field. In addition, the Max pooling performs a noise suppressant when getting only the max value and discarding the others.
 Max pooling (Source: Standford)
Max pooling (Source: Standford)
 Average pooling (Source: Standford)
Average pooling (Source: Standford)
Calculate output’s dimension
This must be the most vital part of this blog. Before diving into some difficult formulas, let me define some syntax that gonna be used later. The shape of the input image is $(C_{in}, H_{in}, W_{in})$ and the shape of the output feature map should be $(C_{out}, H_{out}, W_{out})$, where $C$ is the number of channels, $H$ is the height and $W$ is the width of the image/feature matrix.
The first thing we need to computate is the shape of the feature map and can also be used for computing the shape of Pooling’s output.
\[H_{out}=\bigg[\frac{H_{in}+2*\text{padding}[0]-\text{dilation}[0]*(\text{kernel_size}[0]-1)-1}{\text{stride}[0]}+1\bigg]\] \[W_{out}=\bigg[\frac{W_{in}+2*\text{padding}[1]-\text{dilation}[1]*(\text{kernel_size}[1]-1)-1}{\text{stride}[1]}+1\bigg]\]The second formula is responsible for computing the total number of parameters for a kernel. If the kernel has the shape $(C, H, W)$ then:
\[\text{# params}= H * W * C + 1 (\text{bias})\]By default, the kernel is a square matrix. Hence, its height is equal to its width. On the other hand, the number of parameters in the Pooling layer is zero, because it is used only for reducing the dimensionality of the feature map.
Dilated Convolution
When building a convolution layer with Pytorch, I came across the term “Dilated Convolution”. OMG! I’ve never seen this term before in any class. So, I tried figuring out what it is through the Internet, but those definitions that I found made me more confused. So, in this cheat sheet, my goal is to explain it in the most intuitive way possible so that everybody can get it easily.
Firstly, let’s check out the definition of “dilated convolution” on GeeksforGeeks:
Dilated Convolution is a technique that expands the kernel (input) by inserting holes between its consecutive elements. In simpler terms, it is the same as convolution but it involves pixel skipping, so as to cover a larger area of the input.
 Dilated Convolution (Source: researchgate)
Dilated Convolution (Source: researchgate)
Intuitively, we use dilated convolution when we need to cover more information without increasing the number parameter of the kernel. In the example above, the 3x3 dilated convolution with $d = 2$ covers a 5x5 receptive field without changing the number parameters. In essence, normal convolution is just a 1-dilated convolution.
According to Geeksforgeeks, here are some advantages of dilated convolution:
- Larger receptive field (i.e. no loss of coverage)
- Computationally efficient (as it provides a larger coverage on the same computation cost)
- Lesser Memory consumption (as it skips the pooling step) implementation
- No loss of resolution of the output image (as we dilate instead of performing pooling)
- Structure of this convolution helps in maintaining the order of the data.
Transposed Convolution
Transposed convolution or Deconvolution is an inverse version of normal convolution, i.e., this operation recovers the shape of a feature map to its original one. By adding rows and columns of zeros, we can emulate the transposed convolution with direct convolution.
 Transposed Convolution (Source: nttuan8)
Transposed Convolution (Source: nttuan8)
By the way, I used this transposed convolution for building the generator in generative adversarial networks.
References
CS230 Convolutional Neural Networks - Standford